

はじめに
組み込みフォントの基礎知識や用語などを解説していくブログ「よくわかる!組み込みフォント」今回は、文字セットと文字コードについての解説と代表的なコード一覧、フォントを検討する上でのポイントをまとめました。
文字セット
文字セットとは、コンピュータ上で文字や記号を表示や交換できるようにするために定められた文字の集合(character set)をいいます。
代表的な文字セット
日本語文字セット
公的規格(JIS:日本産業規格「旧:日本工業規格」で定めた規格)
- JISX0201 :158文字(JIS半角文字)
- JISX0208 :6,879文字(JIS非漢字、第1水準・第2水準漢字)
- JISX0213 :11,223文字(JISX0208に第3水準・第4水準漢字を追加)
特定の企業や団体が定めた規格
●アドビシステムズ社が日本語DTP用に定めた文字セット
- Adobe-Japan1-3:9,354文字
- Adobe-Japan1-4:15,444文字
- Adobe-Japan1-5:20,317文字
- Adobe-Japan1-6:23,058文字
●マイクロソフト社がWindowsで定めた文字セット
- マイクロソフト標準文字セット(Windows31J):7,881文字
JISX0208、JISX0201、NEC特殊文字、NEC選定IBM拡張文字、IBM拡張文字
※モリサワが提供している組込用途での日本語文字セットはこちらを採用しています。
外字セット
標準的な文字セット規格に含まれない文字で、用途ごとに規格化されているものもあります。
以下は代表的な外字セット(ARIB外字)です。JIS規格で定められた文字以外にデジタル放送用途に必要な日本語の外字で、社団法人電波産業会(ARIB)によって規格化されています。
主なARIB規格
- ARIB STD-B24:デジタル放送におけるデータ放送符号化方式と伝送方式規格
- ARIB STD-B3:FM多重放送の運用上の標準規格
- ARIB STD-B62:デジタル放送におけるマルチメディア符号化方式規格
ARIB外字セット
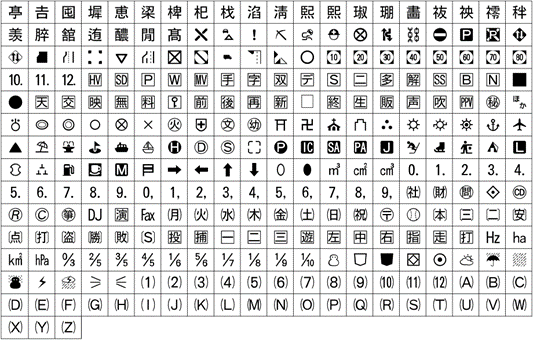
■主な利用製品:デジタルテレビ・レコーダー、カーナビなどデジタル放送受信機器
文字コード
文字コードは、文字セット(文字の集合)をコンピュータで扱うために、文字や記号ひとつひとつに割り当てられた固有の数値(character code)のことです。
※文字セットと文字コードは同意語として理解され使われることも多い。
以下は米国工業標準を定めるANSIがデータ互換用の標準的な文字コード(7-Bit ASCII)です。元々米国の国内標準規格でしたが、現在は国際標準化機構(ISO)によって国際標準(ISO-646)となっています。
ASCIIコード表
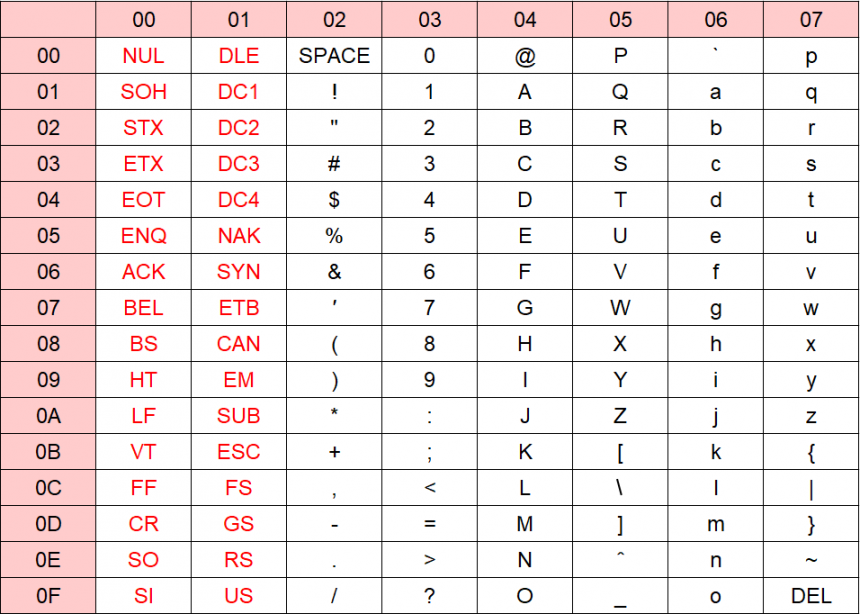
赤字は制御文字といい、文字コードで定義される文字のうち、ディスプレイ・プリンター・通信装置などの出力装置を動作(制御)させるために使う文字です。「文字」と呼んでいますがディスプレイやプリンターには出力されないため、非表示文字(non-printing character)とも呼びます。
1バイト文字コード
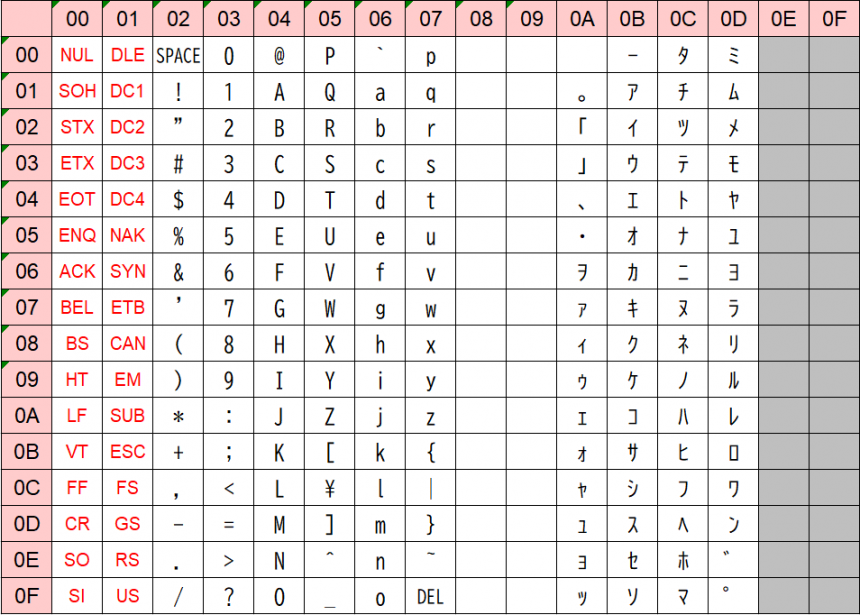
1バイト(8ビット:0~255)のデータで表す文字。数字やアルファベットを収録したASCIIを拡張して日本語の半角文字を収録したJISX0201(ANK文字)、欧州諸国の言語を収録したISO8859などが代表的で文字の種類が少ない言語で使われています。
JISX0201の文字コード表
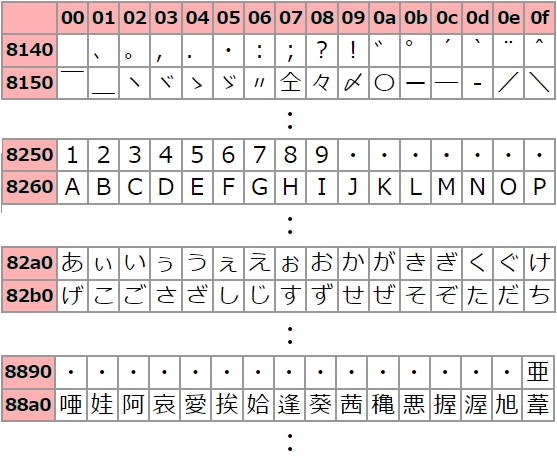
2バイト文字コード
2バイト(16ビット:0~65,535)のデータで表す文字。日本語や中国語、韓国語のように文字数が多く1バイト(0~255)の値では表しきれない言語で使われています。
JISX0208の文字コード表
代表的な文字コード
Shift JIS
JIS X 0208を再配置(シフト)して2バイト文字と1バイト文字を混在して扱えるようにした文字コード
Unicode
世界中の文字を共通の文字セットとして扱えるように考えた文字コード
※最新15.0.0(2022年9月):149,186文字を収録
以下の符号化方式が一般的です。
UTF8:8ビット単位(1~4バイトまでの可変長)で表す符号化方式
UTF16:16ビット単位(2~4バイトの固定長)で表す符号化方式
GB2312
中国語簡体字の文字コード
中国(中国大陸)で使われている。
GB18030
中国語の文字コード
簡体字や繁体字、日本、韓国などで使われる漢字も含み、GB2312を内包している。
Big5
中国語繁体字の文字コード
台湾・香港・マカオで使われている。
KSX1001
韓国語の文字コード
ハングルや漢字が含まれている。
■コードページ
各国語ごとにまとめられた文字コードです。コードページを切り替えて各言語で使用。
まだコンピュータの性能が低かった頃、世界中の文字を一つで扱うことができなかったため、それぞれの言語ごとに収録。
ISO/IEC 8859:代表的な1バイト文字コード。主に欧州諸国言語を定義
| ISO8859-1(Latin1) | 英語/ドイツ語/フランス語/イタリア語/スペイン語/ポルトガル語/ オランダ語/デンマーク語/スウェーデン語/ノルウェー語/フィンラ ンド語/アイスランド語/アイルランド語/アルバニア語など |
| ISO8859-2(Latin2) | クロアチア語/チェコ語/スロバキア語/スロベニア語/ハンガリー 語/ポーランド語/ルーマニア語など |
| ISO8859-3(Latin3) | エスペラント語/マルタ語など |
| ISO8859-4(Latin4) | エストニア語/ラトビア語/リトアニア語など |
| ISO8859-5(Cyrillic) | ロシア語/ウクライナ語/セルビア語/ブルガリア語/ベラルーシ語 /マケドニア語など |
| ISO8859-6(Arabic) | アラビア語 |
| ISO8859-7(Greek) | ギリシャ語 |
| ISO8859-8(Hebrew) | ヘブライ語 |
| ISO8859-9(Latin5) | トルコ語 |
| ISO8859-10(Latin6) | イヌイット語/グリーンランド語/サーメ語/ラップ語など |
| ISO8859-11 | タイ語 |
| ISO8859-14(Latin8) | ウェールズ語/ゲール語/ケルト語など |
WindowsCodePage(CP):MicrosoftがWindowsで使用するために定義
| CP932 | 日本語(ShiftJIS) |
| CP936 | 中国語簡体字(GB2312) |
| CP949 | 韓国語(KSC5601:1987) |
| CP950 | 中国語繁体字(Big5) |
| CP1252 | 英語/ドイツ語/フランス語/イタリア語/スペイン語/ポルトガル語/オランダ語/ スウェーデン語/フィンランド語/デンマーク語/ノルウェー語など ※ISO8859-1に「€マーク」などいくつか追加文字を含む文字を収録 |
| CP1250 | チェコ語、スロバキア語/ポーランド語/ルーマニア語/ハンガリー語/スロベニア 語/クロアチア語など |
| CP1251 | ロシア語/ウクライナ語/セルビア語/ブルガリア語/ベラルーシ語/マケドニア語 など |
| CP1253 | ギリシャ語 |
| CP1255 | ヘブライ語 |
| CP1256 | アラビア語 |
| CP1257 | エストニア語/ラトビア語/リトアニア語など |
| CP1258 | ベトナム語 |
| CP874 | タイ語 |
エンコーディング
一定の規則に基づいてデータ変換することをいい、ここでは各文字をどの文字コードに割り当てるかをいいます。
フォントをご検討の際は、どの言語・文字セット・文字コードが必要かをご確認ください。
- 必要な言語(対応国):【例】日本語、英語、ドイツ、フランス
- 必要な文字セット:【例】JISX0208、ISO8859-1
- 文字コード:【例】Unicode(UTF16)
利用時の入力の有無など、使用方法によっても必要な文字セットは変わる場合がありますので、具体的な使用方法なども含めご相談ください。
今回の文字セットと文字コードの解説は以上になります。
ご質問などがあれば直接メールにてお問合せください。
問合せ先
株式会社モリサワ セールスイノベーション課 salesinnovation@morisawa.co.jp