

소개
편입 폰트의 기초 지식이나 용어 등을 해설해 가는 블로그 「잘 알 수 있다!
문자 세트
문자 집합이란 컴퓨터에서 문자나 기호를 표시하거나 교환할 수 있도록 하기 위해 정해진 문자 집합(character set)을 말합니다.
대표 문자 세트
일본어 문자 세트
공적 규격(JIS:일본 산업 규격 「구:일본 공업 규격」으로 정한 규격)
- JISX0201 :158문자(JIS반각 문자)
- JISX0208 :6,879문자(JIS 비한자, 제1 수준·제2 수준 한자)
- JISX0213 :11,223문자(JISX0208에 제3수준・제4수준 한자를 추가)
특정 기업이나 단체가 정한 규격
●Adobe Systems, Inc.가 일본어 DTP 용으로 정한 문자 세트
- Adobe-Japan1-3:9,354자
- Adobe-Japan1-4:15,444자
- Adobe-Japan1-5:20,317자
- Adobe-Japan1-6:23,058자
●Microsoft가 Windows에서 정한 문자 세트
- Microsoft 표준 문자 집합(Windows31J): 7,881자
JISX0208, JISX0201, NEC 특수 문자, NEC 선정 IBM 확장 문자, IBM 확장 문자
※모리사와가 제공하고 있는 임베디드 용도로의 일본어 문자 세트는 이쪽을 채용하고 있습니다.
외자 세트
표준적인 문자 세트 규격에 포함되지 않는 문자로, 용도 마다 규격화되고 있는 것도 있습니다.
다음은 대표적인 외자 세트(ARIB 외자)입니다. JIS 규격으로 정해진 문자 이외에 디지털 방송 용도에 필요한 일본어의 외자로, 사단법인 전파 산업회(ARIB)에 의해 규격화되고 있습니다.
주요 ARIB 표준
- ARIB STD-B24:디지털 방송에 있어서의 데이터 방송 부호화 방식과 전송 방식 규격
- ARIB STD-B3 : FM 다중 방송의 운영상의 표준
- ARIB STD-B62: 디지털 방송의 멀티미디어 인코딩 방식 표준
ARIB 외자 세트
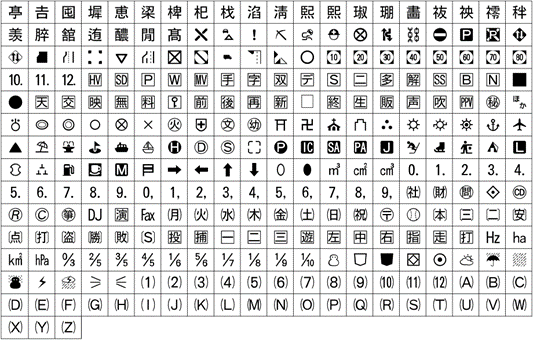
■주요 이용제품:디지털 TV・레코더, 카 내비게이션 등 디지털 방송 수신 기기
문자 코드
문자 코드는 문자 집합(문자 집합)을 컴퓨터에서 처리하기 위해 문자나 기호 하나에 할당된 고유 숫자(character code)입니다.
※ 문자 세트와 문자 코드는 동의어로 이해되어 사용되는 경우도 많다.
다음은 미국 산업 표준을 정하는 ANSI가 데이터 호환을 위한 표준 문자 코드(7-Bit ASCII)입니다. 원래 미국의 국내 표준 규격이었지만, 현재는 국제 표준화 기구(ISO)에 의해 국제 표준(ISO-646)이 되고 있습니다.
ASCII 코드 테이블
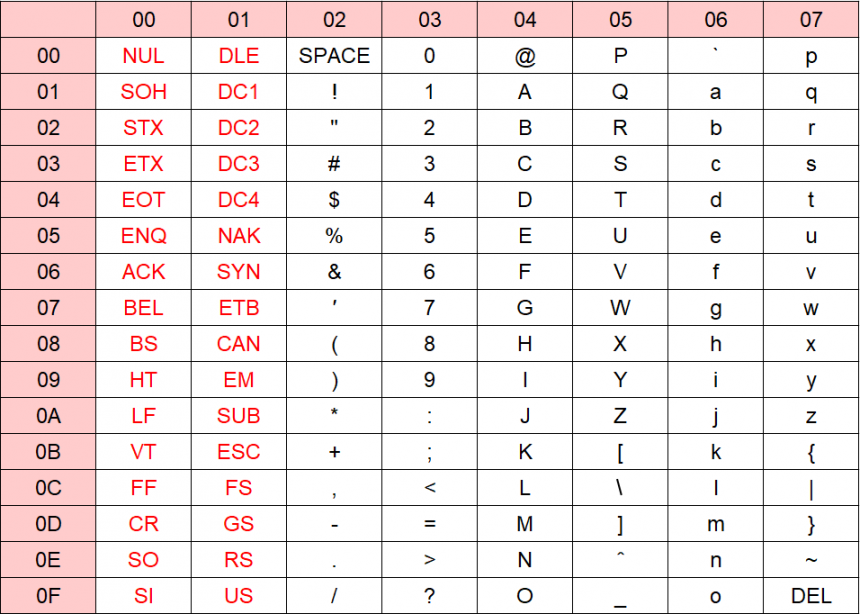
적자는 제어 문자라고 하며 문자 코드로 정의되는 문자 중 디스플레이, 프린터, 통신 장치 등의 출력 장치를 동작(제어)시키기 위해 사용하는 문자입니다. 「문자」라고 부르고 있습니다만 디스플레이나 프린터에는 출력되지 않기 때문에, 비표시 문자(non-printing character)라고도 부릅니다.
1바이트 문자 코드
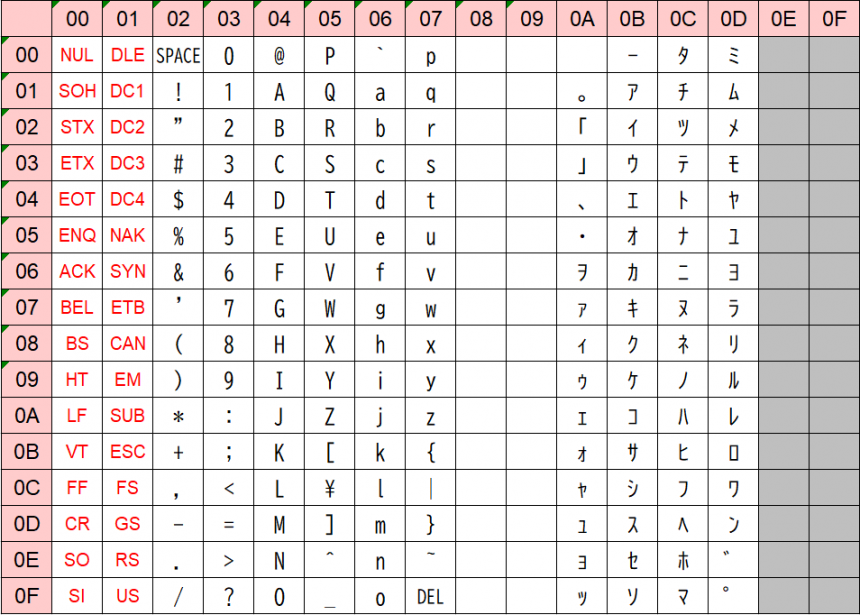
1바이트(8비트: 0~255)의 데이터로 나타내는 문자. 숫자나 알파벳을 수록한 ASCII를 확장하여 일본어의 반각 문자를 수록한 JISX0201(ANK 문자), 유럽 국가의 언어를 수록한 ISO8859 등이 대표적이고 문자의 종류가 적은 언어로 사용되고 있습니다.
JISX0201의 문자 코드 표
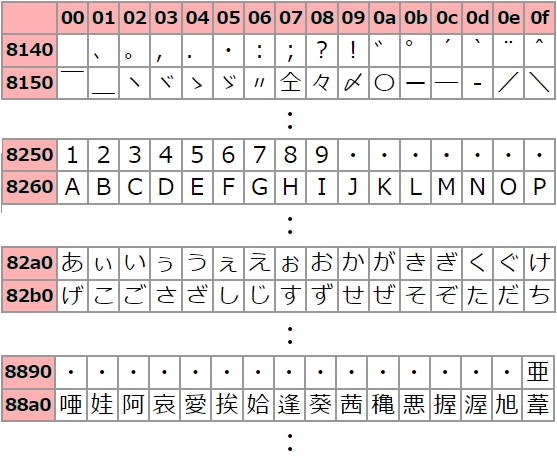
2바이트 문자 코드
2바이트(16비트: 0~65,535)의 데이터로 나타내는 문자. 일본어나 중국어, 한국어와 같이 문자수가 많아 1바이트(0~255)의 값으로는 표현할 수 없는 언어로 사용되고 있습니다.
JISX0208의 문자 코드 표
대표 문자 코드
Shift JIS
JIS X 0208을 재배치 (시프트)하여 2 바이트 문자와 1 바이트 문자를 혼합하여 처리 할 수 있도록 한 문자 코드
유니코드
전세계 문자를 공통 문자 세트로 취급 할 수 있도록 생각한 문자 코드
※최신 15.0.0(2022년 9월):149,186문자를 수록
이하의 encode 방식이 일반적입니다.
UTF8: 8비트 단위(1~4바이트까지의 가변 길이)로 나타내는 부호화 방식
UTF16:16비트 단위(2~4바이트의 고정 길이)로 나타내는 부호화 방식
GB2312
중국어 간체 문자 코드
중국(중국대륙)에서 사용되고 있다.
GB18030
중국어 문자 코드
간체자와 번체자, 일본, 한국 등에서 사용되는 한자도 포함해 GB2312를 내포하고 있다.
Big5
중국어 번체자 문자 코드
대만·홍콩·마카오에서 사용되고 있다.
KSX1001
한국어 문자 코드
한글과 한자가 포함되어 있습니다.
■코드 페이지
각국어마다 정리된 문자 코드입니다. 코드 페이지를 전환하여 각 언어로 사용.
아직 컴퓨터의 성능이 낮았을 무렵, 전세계의 문자를 하나로 취급할 수 없었기 때문에, 각각의 언어마다 수록.
ISO/IEC 8859: 대표적인 1바이트 문자 코드. 주로 유럽 국가 언어 정의
| ISO8859-1(Latin1) | 영어/독일어/프랑스어/이탈리아어/스페인어/포르투갈어/ 네덜란드어/덴마크어/스웨덴어/노르웨이어/핀라 엔드어/아이슬란드어/아일랜드어/알바니아어 등 |
| ISO8859-2(Latin2) | 크로아티아어/체코어/슬로바키아어/슬로베니아어/헝가리 단어/폴란드어/루마니아어 등 |
| ISO8859-3(Latin3) | 에스페란토어/몰타어 등 |
| ISO8859-4(Latin4) | 에스토니아어/라트비아어/리투아니아어 등 |
| ISO8859-5(Cyrillic) | 러시아어/우크라이나어/세르비아어/불가리아어/벨로루시어 /마케도니아어 등 |
| ISO8859-6(Arabic) | 아랍어 |
| ISO8859-7(Greek) | 그리스어 |
| ISO8859-8(Hebrew) | 히브리어 |
| ISO8859-9(Latin5) | 터키어 |
| ISO8859-10(Latin6) | 이누이트어/그린란드어/서메어/랩어 등 |
| ISO8859-11 | 태국어 |
| ISO8859-14(Latin8) | 웨일즈어/게일어/켈트어 등 |
WindowsCodePage(CP): Microsoft가 Windows에서 사용하도록 정의
| CP932 | 일본어(ShiftJIS) |
| CP936 | 중국어 간체(GB2312) |
| CP949 | 한국어 (KSC5601:1987) |
| CP950 | 중국어 번체(Big5) |
| CP1252 | 영어/독일어/프랑스어/이탈리아어/스페인어/포르투갈어/네덜란드어/ 스웨덴어/핀란드어/덴마크어/노르웨이어 등 ※ISO8859-1에 「€ 마크」등 일부 추가 문자를 포함한 문자를 수록 |
| CP1250 | 체코어, 슬로바키아어/폴란드어/루마니아어/헝가리어/슬로베니아어 단어/크로아티아어 등 |
| CP1251 | 러시아어/우크라이나어/세르비아어/불가리아어/벨로루시어/마케도니아어 등 |
| CP1253 | 그리스어 |
| CP1255 | 히브리어 |
| CP1256 | 아랍어 |
| CP1257 | 에스토니아어/라트비아어/리투아니아어 등 |
| CP1258 | 베트남어 |
| CP874 | 태국어 |
인코딩
특정 규칙을 기반으로 데이터를 변환하는 것이 좋습니다. 여기서는 각 문자를 어떤 문자 코드에 할당할지 말합니다.
글꼴을 고려할 때 어떤 언어, 문자 세트, 문자 코드가 필요한지 확인하십시오.
- 필요한 언어(대응국):【예】일본어, 영어, 독일, 프랑스
- 필요한 문자 세트 : 【예】 JISX0208, ISO8859-1
- 문자 코드:【예】Unicode(UTF16)
이용시의 입력의 유무 등, 사용 방법에 따라서도 필요한 문자 세트는 바뀌는 경우가 있기 때문에, 구체적인 사용 방법등도 포함해 상담해 주십시오.
이번 문자 세트와 문자 코드의 해설은 이상이 됩니다.
질문 등이 있으면 직접 메일로 문의하십시오.
문의처
주식회사 모리사와 세일즈 이노베이션과 salesinnovation@morisawa.co.jp